

2025-08-26 14:02:17
Hash ,一般叫做散列算法,就是把任意长度的输入通过散列算法,变换成固定长度的输入,相当于一种压缩映射,将任意长度的消息压缩到某一固定长度的消息摘要的函数。
• 加法Hash;把输入元素一个一个的加起来构成最后的结果
/**
* 加法hash
*
* @param key
* 字符串
* @param prime
* 一个质数
* @return hash结果
*/
public static int additiveHash(String key, int prime) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); i++)
hash += key.charAt(i);
return (hash % prime);
}• 位运算Hash;这类型Hash函数通过利用各种位运算(常见的是移位和异或)来充分的混合输入元素
/**
* 旋转hash
*
* @param key
* 输入字符串
* @param prime
* 质数
* @return hash值
*/
public static int rotatingHash(String key, int prime) {
int hash, i;
for (hash = key.length(), i = 0; i < key.length(); ++i)
hash = (hash << 4) ^ (hash >> 28) ^ key.charAt(i);
return (hash % prime);
// return (hash ^ (hash>>10) ^ (hash>>20));
}• 乘法Hash;这种类型的Hash函数利用了乘法的不相关性(乘法的这种性质,最有名的莫过于平方取头尾的随机数生成算法,虽然这种算法效果并不好);
static int bernstein(String key)
{
int hash = 0;
int i;
for (i=0; i<key.length(); ++i) hash = 33*hash + key.charAt(i);
return hash;
}jdk5.0里面的String类的hashCode()方法也使用乘法Hash;32位FNV算法
int M_SHIFT = 0;
public int FNVHash(byte[] data) {
int hash = (int) 2166136261L;
for(byte b : data)
hash = (hash * 16777619) ^ b;
if(M_SHIFT == 0)
return hash;
return (hash ^ (hash >> M_SHIFT)) & M_MASK;
}改进后的 FNV 算法
public static int FNVHash1(String data) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < data.length(); i++)
hash = (hash ^ data.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
return hash;
}常见的还有乘以一个不断改变的数
static int RSHash(String str) {
int b = 378551;
int a = 63689;
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash = hash * a + str.charAt(i);
a = a * b;
}
return (hash & 0x7FFFFFFF);
}• 除法Hash;除法和乘法一样,同样具有表面上看起来的不相关性。不过,因为除法太慢,这种方式几乎找不到真正的应用
• 查表Hash;查表Hash最有名的例子莫过于CRC系列算法。虽然CRC系列算法本身并不是查表,但是,查表是它的一种最快的实现方式。查表Hash中有名的例子有:Universal Hashing和Zobrist Hashing。他们的表格都是随机生成的。
• 混合Hash;混合Hash算法利用了以上各种方式。各种常见的Hash算法,比如MD5、Tiger都属于这个范围。它们一般很少
inline int hashcode(const int *v)
{
int s = 0;
for(int i=0; i<k; i++)
s=((s<<2)+(v[i]>>4))^(v[i]<<10);
s = s % M;
s = s < 0 ? s + M : s;
return s;
}在面向查找的Hash函数里面使用
环 hash 计算步骤
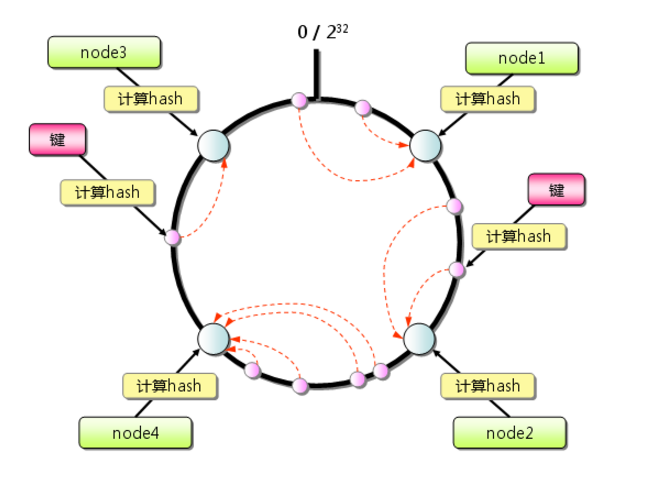
image
数据倾斜是指,当机器不多时,几台机器在环上面贴的很近,分布是不是很均匀,会导致大部分数据集中到这几台机器上,这样就产生了数据倾斜问题。
引入了虚拟机器概念,一台机器需要在环上映射出多个这个位置,比如 我们用机器的 ip 来 hash ,这样就实现了一台物理机映射出多个虚拟机器的编号。




